
About
Experiences
Education
News
- Nov 2025 Selected (top 10%) to give a talk at the KAUST Rising Stars in AI Symposium 2026.
- Oct 2025 Video-MMLU received the Outstanding Paper Award at the ICCV 2025 Knowledge-Intensive Multimodal Reasoning Workshop, along with a travel grant.
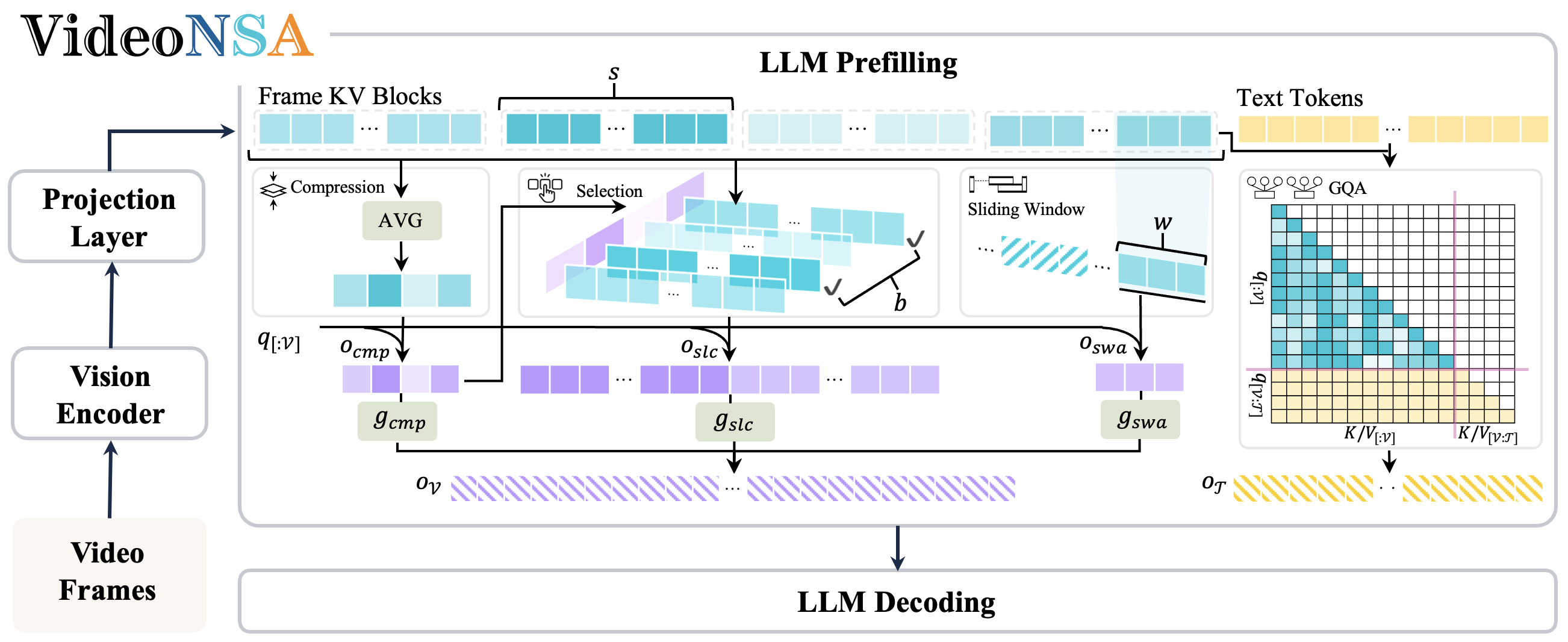
- Oct 2025 We release VideoNSA, a hardware-aware native sparse attention mechanism for video understanding.
- Sep 2025 Invited talk at Lambda AI titled From Seeing to Thinking.
- Sep 2025 One paper accepted by ICCV 2025 KnowledgeMR Workshop.
- Aug 2025 Our paper MovieChat+: Question-aware Sparse Memory for Long Video Question Answering is accepted by IEEE TPAMI.
Selected Publications and Manuscripts
* Equal contribution.
Also see Google Scholar.


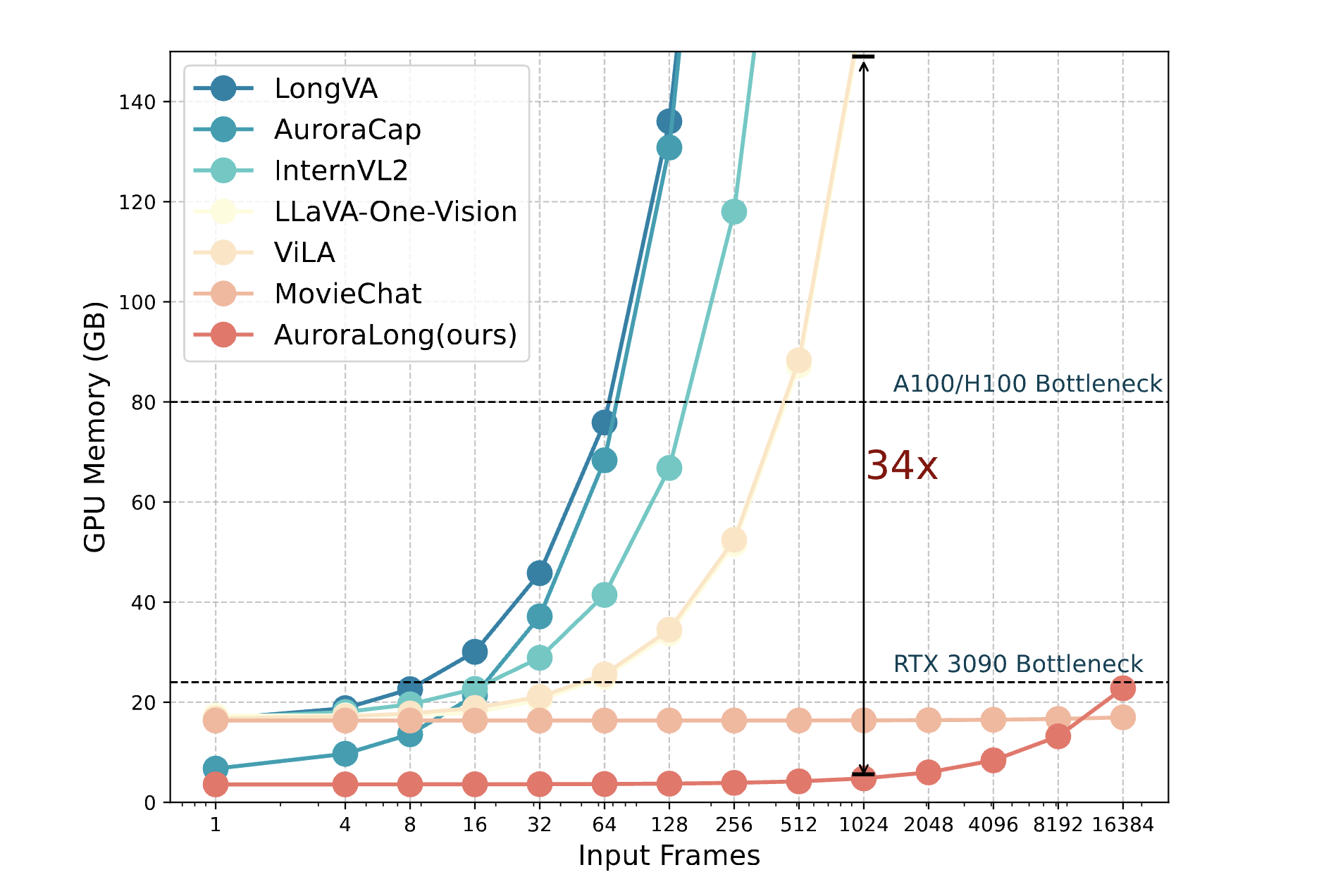
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
ICCV, 2025
Video-MMLU uses a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states to solve long video understanding tasks.


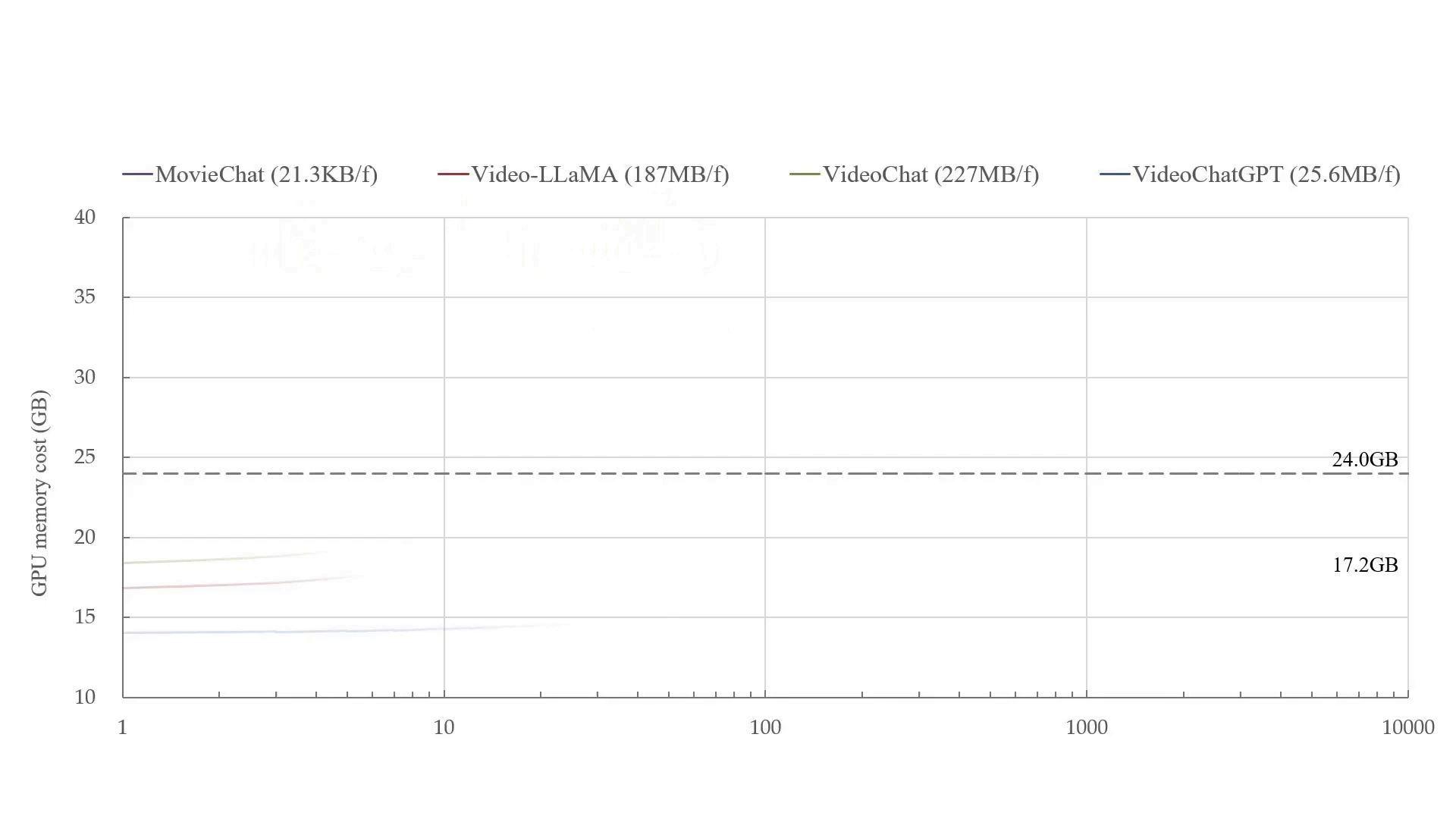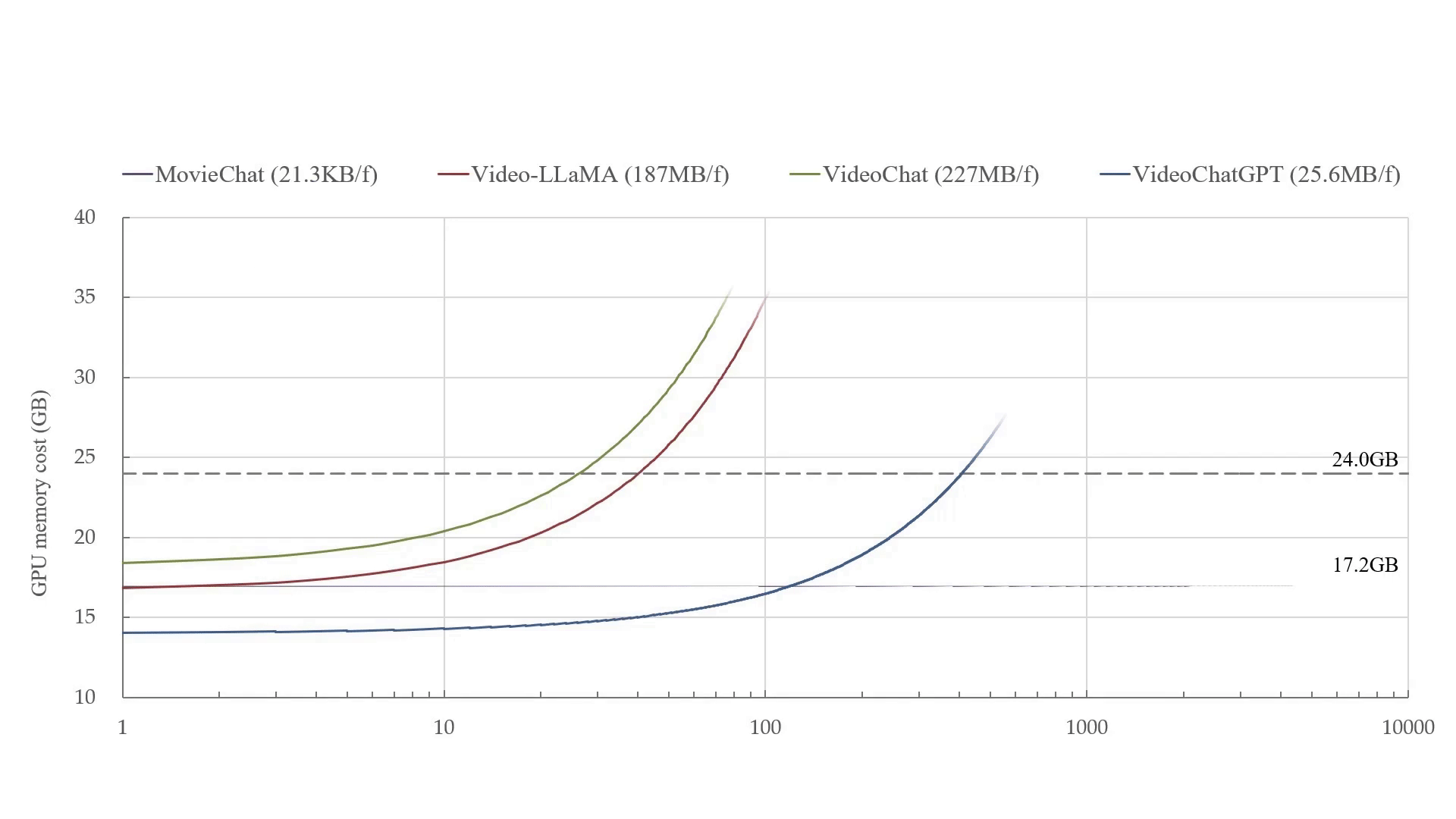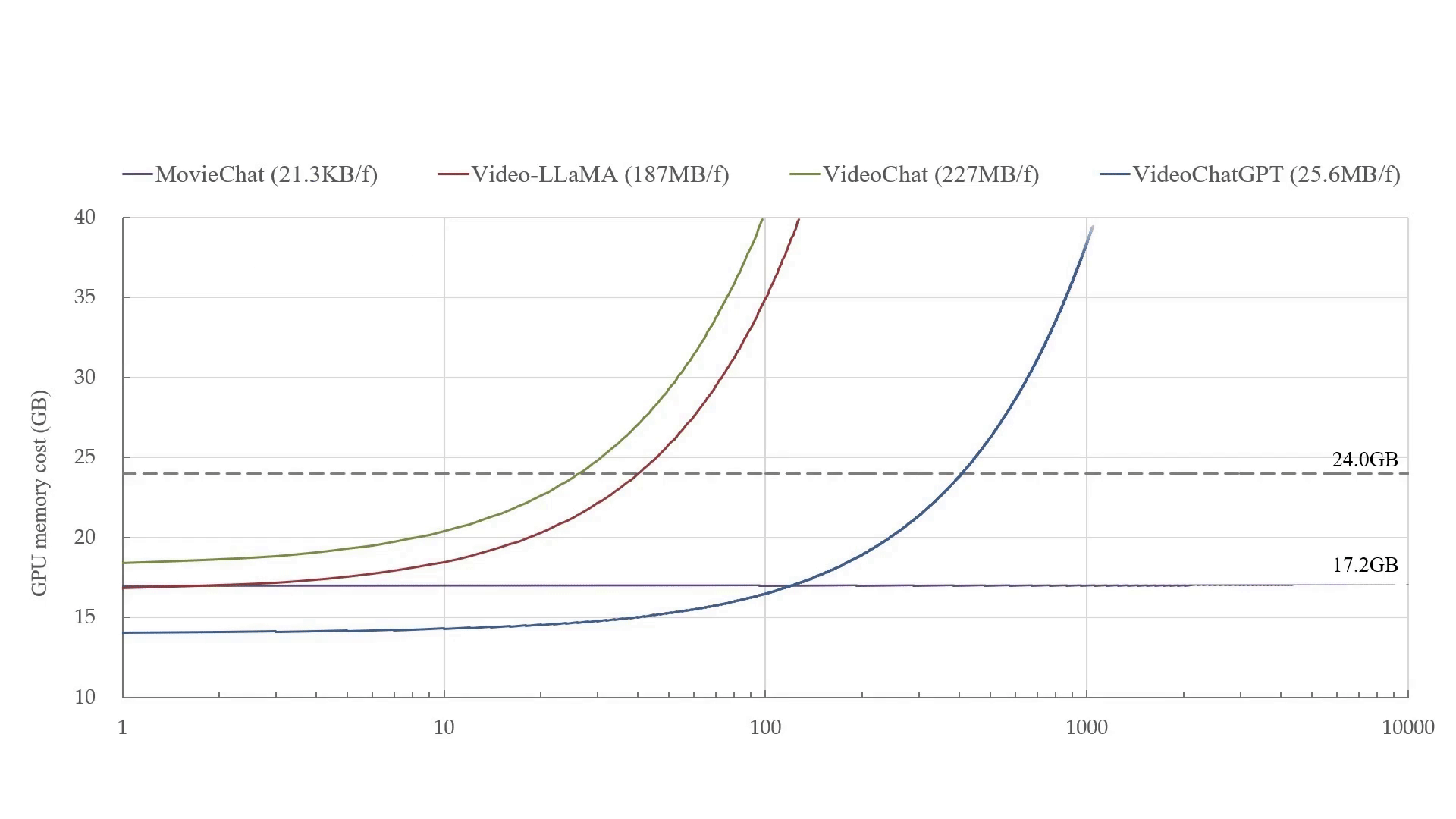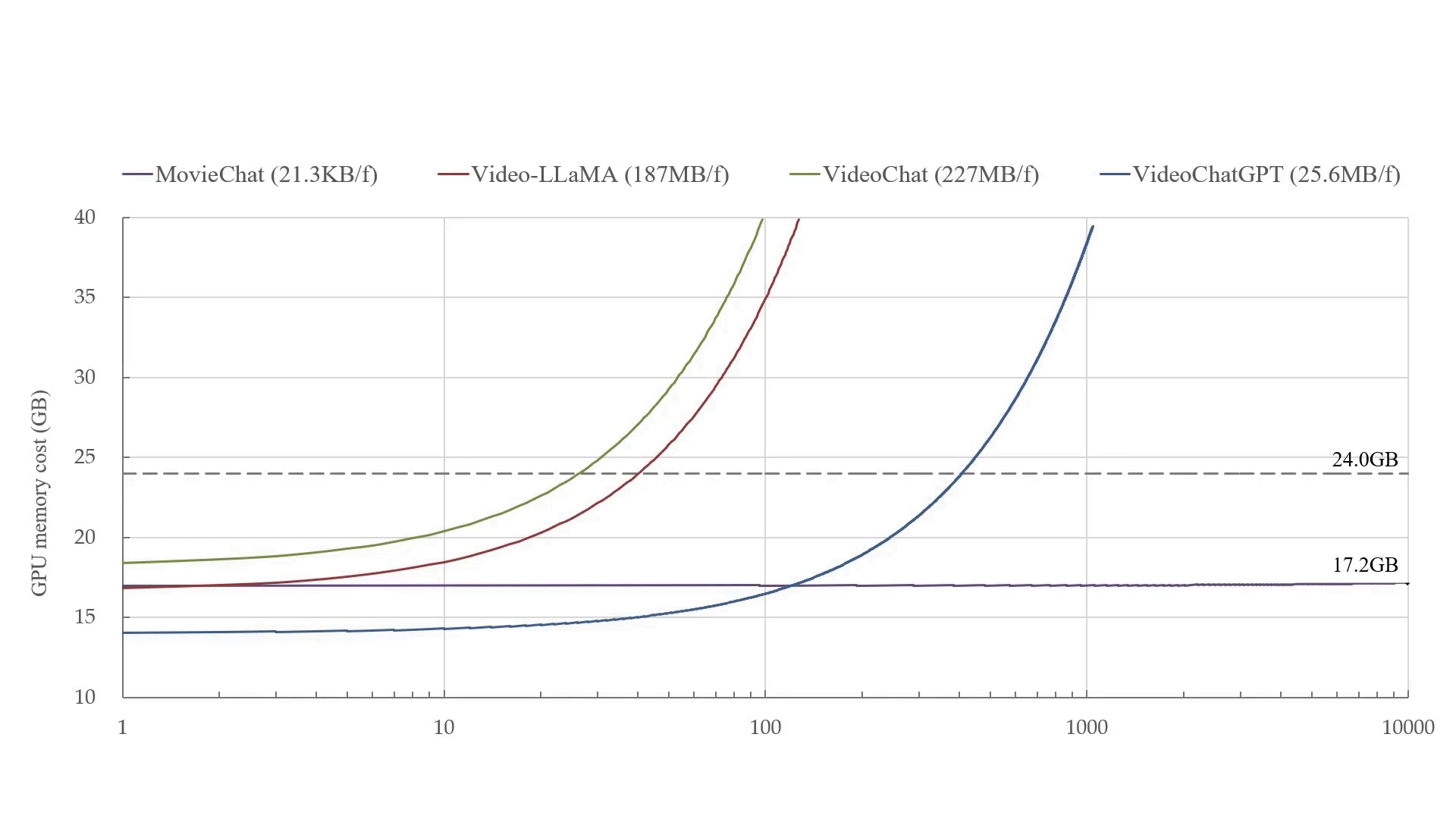

Teaching Assistant
Teaching Assistant (TA), with Prof. Gaoang Wang
Selected Honors & Awards
- KAUST Rising Stars in AI Symposium 2026
- Lambda AI Cloud Credits Grant Sponsorship, 2025
- National Scholarship, 2025 (Zhejiang University)
- National Scholarship, 2024 (Zhejiang University)
- National Scholarship, 2021 (Dalian University of Technology)
Top